
COURSERA Deep Learning Specialization 과정의 진행하면서 익힌 내용을 공유한다.
Andrew Ng 교수님께서 강의하시는 내용으로 총 5개의 Course 로 구성되어 다. 각 Course 별 목차는 다음 포스트를 참고하기 바란다.
Course1. Neural Networks and Deep Learning
Week1. Introduction to deep learning
첫 번째 주차는 소개 단계로, 지도학습과 비지도학습의 구분, X인자를 통한 Y 인자의 예측을 어떻게 할 것인가? 하는 문제들을 소개하고, 향후 학습하게 될 딥러닝 관련 신경망이란 용어에 대해서도 소개한다. 딥러닝이 전통적인 머신러닝에 비해서 데이터가 많아질 경우 갖는 장점에 대해서 알아보고, 5개 강좌의 개략적인 학습 범위와 내용에 대해서도 소개한다.
이 전문가 과정에서는 “Heroes of Deep Learning” 이라고 해서 이 분야의 유명인들을 인터뷰하는 섹션이 있다. 첫 주차에는 그 유명한 “Geoffrey Hinton” 교수가 나와 학위 과정 및 연구들에 대해서 아주 재미난 인터뷰를 진행한다. 개인적으로 첫 주차의 하이라이트는 이 인터뷰인거 같았다.
Week2. Neural Networks Basics
두 번째 주차에서는 “Logistic Regression” 을 다룬다. 3주, 4주차에 접할 Shallow Neural Network 과 Deep Neural Network 을 이해하기에 앞서서 단일 노드로 구성된 Logistic Regression 에 대해서 충분히 연습하게 된다. 즉, 입력값에 가중치와 상수를 더한 z 값을 구한 뒤 ( z = w^Tx+b ), 활성함수인 시그모이드를 통해 a 를 얻는 ( a = \sigma(z) ) 과정을 학습하게 된다.
학습의 결과가 비용함수 (Cost Function) 로 평가되기 때문에 Gradient Descent 알고리즘으로 Cost Function (비용함수)의 변화에 대해서 확인해 본다. 이를 이용하여 각 가중치와 상수를 업데이트하는 방법을 알아 보기 위해서 미분된 결과를 연쇄 법칙 (Chain Rule) 으로 따라가는 과정을 비교적 자세히 살펴 본다. 이는 좀 더 복합한 네트워크의 Back Propagation 을 학습하기에 앞서서 단일 노드로 그 과정을 기초적으로 확인해 보고자 함이다.
단일 학습 데이터를 m 개의 학습 데이터로 확장시켜 이에 대한 수식을 살펴본다. 이는 이 과정 내내 사용될 m 개 학습 데이터에 대해서 표현과 계산 방법을 알아 보는 중요한 부분이다. m 개 데이터를 학습시키는 것을 Python Code 로 구현하기 위해서 친절하게도 이론적 수식을 Python Code 로 전환하는 과정을 배운다. 일차원적인 산술연산을 직접하는 것이 아니라 Python Numpy 에서 제공하는 matrix 간 연산을 통해서 효율적으로 진행하는 방법을 배운다. 그 과정에서 Numpy 의 Broadcasting 방법도 알게 된다. 개인적으로 이러한 식의 Guide 는 굉장히 도움이 되는 것 같다.
Week3. Shallow Neural Networks
Logistic Regression 이 단일 노드 (입력 이후 바로 출력층이 나오는) 로 구성된 데 비해서, Shallow Neural Network 부터는 은닉층 (Hidden Layer) 가 등장하게 된다. 단지 그 차이뿐이다. 은닉층이 여러 개가 되면 Deep Neural Networks 로 가게 되는 것이다. 이 주차의 과정은 Logistic Regression 에서 Deep Neural Network 으로 전환되는 과정의 징검다리라고 이해하면 된다. 따라서 내용이 2주차와 비슷하게 느껴질 수 있다. 똑같은 걸 왜 자꾸 하지라는 의문이 들거나 지겨워 질 수 있는데 그럴 때는 빠르게 넘어 간 뒤 다시 한번 살펴보는 것도 좋을거 같다.
가장 큰 차이는 은닉층에 또 다른 Node 들이 있다는 것이고, 최초 인풋이 은닉층을 거치면 노드(Unit) 개수만큼의 또 다른 인풋이 되어 최종 출력층으로 연결된다는 것이다. 이것을 표현하는 방법과 수식, 다시 이를 Python Code 화 하는 과정을 학습하게 된다.
2주차에서 시그모이드(sigmoid) 활성함수만을 살펴 보았다면 이 과정에서는 tanh 나 ReLU 를 확인하게 된다. 그리고 이들 활성함수의 우수함에 대해서도 확인하게 된다. 그리고 활성함수가 왜 필요한지, 왜 이런 비 선형 함수를 넣어야 하는지를 확인하게 된다. 2주차에서 학습했던 미분의 연쇄 법칙을 은닉층을 포함하여 다시 확인해 본다. 마지막으로 가중치 값들과 상수는 랜덤 초기화하는 것에 대해서도 알아 본다.
이 주차의 히어로는 Deep Learning 책으로도 유명한 “Ian Goodfellow” 이다.
Week4. Deep Neural Network
첫 번째 강좌의 마지막 주차로, 아마 4번째 주차로 오기까지 결코 쉽지만은 않았으리라 생각된다. “모두를 위한 딥러닝 시즌1” (개인적으로 김성훈 교수님이 단독으로 진행하는 시즌1이 시즌2 보다 더 좋았다.) 을 듣거나 몇 개의 교재를 통해 Python 으로 Gradient Descent 학습 알고리즘을 실습해 보신 분들은 좀 더 수월하게 진행했을 것이지만 처음으로 Coursera 강의를 들은 분들은 꽤 어려움을 겪었으리라 짐작한다. 특히, Python 프로그래밍 연습을 하지 않은 분들은 실습과정에서 많은 어려움 또는 순간순간 좌절을 겪으셨을 것으로 생각된다. 그런 어려움을 극복하고 마지막 주차에 오시게 된 건 이미 나머지 강좌들을 들을 준비가 되었다고 생각한다.
이 과정에서는 Shallow Neural Network 의 은닉층을 확장하여 2개 이상의 은닉층으로 구성된 Deep Neural Network 를 표현하고 Forward Propagation 및 Backward Propagation 의 진행과정 및 이를 실습하는 것을 학습한다. 또 다른 반복이라고 볼 수 있겠는데, 아무래도 층이 많아지다보니 수식도 좀 더 복잡해 진다. 따라서 matrix 연산에서의 차원을 맞추는 방법 같은 것도 Guide 해 준다. XOR 문제를 풀기위한 역사를 되짚어 보면서 Deep Neural Network 를 사용하는 이유를 설명한다.
이 주차의 하이라이트는 “Building Blocks of Deep Neural Network” 비디오인데, Forward Propagation 과 Backward Propagation 으로 이어지는 내용을 직관적으로 설명해 주고 있다. 보면서 무릎을 탁 치게 할 정도 였다. Cost Function 에서 Backward Propagation 으로 넘어가는 과정을 잘 이해하지 못했었는데, 이 비디오를 보면서 깨닫게 되었다.
다음 강좌에서 진행될 하이퍼 파라미터란 무엇인지 알아보고, 뇌 신경망과의 짧은 비교를 하면서 첫 번째 강좌는 끝이 난다. (물론 실습 과제가 남았지만;;)
Course2. Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
Week1. Practical aspects of Deep Learning
첫 번째 강좌가 Deep Neural Network 를 수식으로 표현하고 비용 함수에 대해서 확인하고 Back Propagation 하는 방법과 이를 실습과정으로 살펴 봤다면, 이 번 강좌는 본격적으로 만들어 놓은 Deep Neural Network 를 다듬고 성능을 향상시키는 방법에 대해서 알아 본다. 이 부분부터는 이론적인 측면과 실험적인 측면이 모두 필요한 내용이라서, 비디오만 듣게 될 경우 별로 와 닿지 않게 된다.
사실 강좌2와 강좌3의 내용은 실전적인 부분으로 딥러닝을 실전에 적용하는 분들께는 피부로 와 닿을 내용이다. 비디오 개수도 많고 진도도 잘 안 나간다. 다른 유사 강좌를 들었다면 내용들을 가벼운 마음으로 들어도 좋을거 같다. 이 부분은 강사의 철학과 경험에 따라 전달하는 바도 조금씩 틀려진다고 생각된다.
학습의 최대 난제는 학습 데이터(Train Data) 만으로 잘 학습된 모델이 실전(Test) 에 취약하거나, 실전에 강하게 하기 위해서 학습을 약하게 시키면 정확도가 낮아진다는데 있다. 이를 Bias-Variance Trade-off 라고 하는데 Bias 는 모델과 예측의 차이(편차)를 의미하고, Variance 는 학습하는 데이터들 사이의 결과의 변량을 의미한다. 즉, Variance 가 크다는 것은 모델이 다양한 인풋 Data 에 대해 설명력이 떨어진다는 것을 의미한다. (어떤 것 잘 되고 어떤 건 잘 안 되고) Bias 를 줄이기 위해서는 모델을 더 깊이 있게 만들라고 조언하고, Variance 를 줄이기 위해서는 더 많은 데이터를 얻어 학습하거나, Regularization 하라고 한다.
Regularization 에도 많은 기법들이 있는데, Regularization Term 을 도입하는 방법과 (L1, L2 등) Dropout (특정 은닉층의 노드 (Unit) 를 정해진 비율만큼 제거하는 방법), Data 를 임의로 변형시켜 데이터를 풍부하게 하는 것 (Data Augmentation), 학습의 조기 종료(Early Stopping) 등을 설명한다. Early Stopping 의 경우 Orthogonality 를 위배하는 측면도 있다.
입력값에 대한 정규화 (Normalization)나 Vanishing Gradient 를 없애기 위한 가중치 초기화 방법, Gradient 계산이 맞았는지 검증하기 위한 수치적인 Checking 방법도 학습한다.
히어로 인터뷰는 “Yoshua Bengio” 교수님인데, 안타깝게도 아직 제대로 듣지를 못했다. 포스트 작성 후에 시간이 나면 꼭 들어 봐야겠다.
Week2. Optimization algorithms
가장 먼저 소개하는 것은 Mini-batch 방법인데, Weight 를 계산 할 때 Batch 방법은 학습 데이터 전체를 넣고 계산하는 것이고 Stochastic 은 개별 데이터를 하나씩만 넣어서 진행한다. Mini-batch 는 그 중간이라고 생각하면 되겠다.
학습 반복횟수와 헷갈리면 안 되는데, 만약 학습 반복 횟수를 ‘n_iter’ 라고 하고 Mini-batch 반복 횟수를 ‘n_mini’ , 총 학습 데이터 개수를 m 이라고 하면 총 학습은 다음과 같이 된다. n_mini 를 “epoch” 라고 한다.
For n_iter :
….For n_mini :
……..Update_Weights()
|
이런 Mini-Batch 방식의 장점은 Batch 방식의 단점인 연산이 오래걸리는 것을 보완할 수 있고, Stochastic 방식의 matrix 를 활용하지 않는 측면을 보완할 수 있다는데에 있다.
그 다음으로 학습하는 것은 각종 가중치 업데이트 알고리즘들이다. Exponentially weighted average 방법에 대해 알아보고 Momentum 방법도 확인해 본다. Momentum 기법을 살짝 변형한 RMSprop 기법도 살펴본다. 또, 유명한 Adam 방법을 알아 보는데, 이는 Momentum 과 RMSprop 기법을 결합한 것이다.
마지막으로 학습 속도를 증가시키기 위해서 learning rate decay 방식이나, 각 방향의 Gradient 가 감소하는 지점인 Saddle point (말 안장) 에서 Local Optima 에 빠질 수도 있다는 것을 배운다. “Problem of plateaus” 라 불리는 매우 편평한 지점을 만나게 되면 학습이 매우 느려지는 단점도 생기게 된다.
히어로 인터뷰는 ImageNet Challenge 에서 Large Scale Image 분류로 우승을 하여 유명해 진 Yuanqing Lin 과의 인터뷰였다. 미국 NEC 연구소에서도 일했으며, Baidu의 딥러닝 연구소를 총괄하고 있다. Andrew Ng 교수가 Baidu 에 있을 당시의 인연으로(이미 유명하지만) 출연한 것 같다.
Week3. Hyperparameter tuning, Batch Normalization and Programming Frameworks
마지막 주차의 내용은 여러가지가 뒤섞여 있다. 가장 먼저 Hyper Parameter튜닝에 대한 접근법이다. 전에 봤던 책 “Python Machine Learning By Example “에서 봤던 예제에서 GridSearch를 사용하는 것을 보고 당연하게 여겼던 그리드 방식을 좋은 방법이 아니라고 한다. 그리드 방식의 경우 여러 Hyper Parameter 들을 짜여진 그리드에서 확인해 보는 건데, 미리 어떤 Hyper Parameter 가 좋은 결과를 낼지 알 수 없는 상황에서 그리드에 있는 값 만을 테스트하게 되므로 같은 수의 조합이라도 Random 한 조합을 권장한다.
한편, Hyper Parameter 마다 Scale 이 있기 때문에 Hyper Parameter 값 변경시 Scale 에 맞게끔 조정이 필요하다. 한 가지 흥미로운 부분은 실험자의 환경에 따라서 한 가지 모델을 지속적으로 튜닝하는 방법과 여러 모델을 만들고 각기 다른 조건을 주어 병렬적으로 튜닝하는 방법 모두 사용이 가능하다는 것이다.
Batch Normalization 관련해서는 다소 생소한 Concept 이라 이해가 쉽게 가지 않았다. 최초 입력 Feature (X 값) 을 Normalization 하는 것 외에도 중간 은닉층 (Hidden Layer) 에서도 Z 값을 \tilde{z} 로 Normalization 하게 되면 중간 층으로 전달되는 값들의 변동에 조금은 덜 민감해 진다고 한다.
Multiple Classification을 위해서 Softmax Regression 을 사용한다. 출력층의 아웃풋이 여러 개의 확률 값이고 가장 높은 확률 값을 가진 순번이 최종 예측 Label 로 선택이 되는 것이다. Cost Function 도 각 출력 값들의 Cost 를 합산한다.
마지막으로 딥러닝 프레임워크에 대해서 알아본다. 많은 딥러닝 프레임워크들이 있고 각자 장단점이 존재한다. 각 언어마다 강점이 있는 분야가 다르며 어떤 하나만 잘 해도 된다 이런 건 정답이 정해져 있지 않다. 이후 강좌에서 강조하지만, 본인이 참고하고자 하는 내용이 GitHub 에 올라와 있고, 해당 소스가 어떤 프레임워크로 되어 있느냐를 보고 해당 프레임워크를 사용사용하면 된다. 미리부터 그 언어를 대비해 공부할 필요는 없다고 생각된다.
Course3. Structuring Machine Learning Projects
강좌 3는 전체 강좌에서 가장 짧은 2주치 강의밖에 없지만 꽤 진행이 더디다. 실습 과제도 없으며, 대신 “Machine Learning flight simulator” 라는 Case Study (Quiz) 를 진행하게 된다. 제대로 학습을 안 하고 넘어가면 Quiz 통과를 장담할 수 없다. 강좌3의 내용들은 Andrew Ng 교수 표현대로 다른 강의들에서 접하기 힘든 실제적인 내용들을 다루고 있기 때문에 실제 문제상황들을 많이 접해본 분들이라면 많은 도움이 될 것이라 여겨지지만, 그렇지 않은 입문자들에게는 개념적으로도 이해하기 어려운 부분이 될거라 여겨진다. 개인적으로도 끝나고 나니, 에너지가 많이 고갈되는 느낌이었다.
1주차에서는 ML 기법들에 어떤 것들이 있고, 여러 문제상황에 어떻게 대처해야 하는지 소개하면서 문을 연다. 한 가지를 조정하면 여러가지가 같이 영향을 받게 되는 상황이 있는데, 그렇게 되면 조정이 어렵다. 되도록이면 각 조절 장치 (Knob) 들을 조정할 때 영향받는 인자들 간에 직교화 (Orthogonalization) 을 시키라고 조언한다.
Machine Learning 에 다양한 알고리즘과 기법, 튜닝할 Hyper Parameter 들이 있는데, Andrew Ng 교수가 강조하는 부분은 프로젝트 시작할 때 단일한 평가 지표 (Single Evaluation Metric) 를 상정해 놓으라는 것이다. 지표에 의해 새로운 아이디어가 이전 것과 비교해서 좋은지 나쁜지 쉽게 판단할 수 있기 때문에 전체적인 진행속도도 빨라 질 수 있다는 내용이다.
실제적으로 가장 하이라이트 부분은 Train/Dev/Test Set 를 어떻게 구분하고 준비하는가에 대한 부분이다. 학습 데이터를 Train/Dev/Test 3개로 구분하고서, Hyper Parameter Tuning 에는 Dev (Development) Set 을 사용한다. Train/Dev 를 구분할 때 K-fold CV (Cross-Validation; 교차검증) 방식을 많이 사용한다. Dev set 은 그래서 Hold-out set 이라고도 불린다. 여기서 중요한 것은 Dev set 과 Test set 을 동일한 분포를 갖는데서 추출해야 한다는 것이다. 그렇지 않다면, 기껏 Dev set 으로 Train 한 모델이 Test set 으로는 좋지 않은 평가지표가 나올 것이기 때문이다.
| Set | 학습(Train) 사용여부 | Data | 모델링 이슈 |
| Train Set | O | Train Data | 초기 모델링 |
| Dev Set (“Hold-out” cross-validation data set) |
O | Train Data | Hyper Parameter 변경 (# of Hidden Units, Learning rate etc) |
| Test Set | X | Test Data | 최종 모델의 평가지표 산출 (Dev set 과 동일 분포) |
<위 표는 Wikipedia 를 토대로 작성한 것입니다. Wikipedia 에서는 Test set 을 Hold-out set 이라고 하였는데, 강의에서는 Dev set 을 Hold-out Cross Validation set 이라 설명하여 혼동되는 부분이 있습니다. 아마도 전통적인 Machine Learning 책들에서는 단순히 Train 과 Test 만 구분하고 Test set 을 Hold-out 이라고 지칭하는데 그렇게 될 경우 Cross-Validation 같은 경우 Test set 을 사용하게 되어 이 강좌의 설명과 차이나는 부분이 있습니다. 좀 더 명확히 살펴볼 필요가 있습니다.>
그리고 전통적인 Machine Learning 의 Train/Test Set 구분시 70%, 30% 방식이나 Train/Dev/Test 구분을 60%, 20%, 20% 씩으로 구분했으나 대량의 학습 데이터가 있는 경우엔 이야기가 달라진다. Train/Dev/Test 를 98%, 1%, 1% 이런식으로 해도 괜찮다. (물론 이런 경우는 K-fold Cross Validation 도 필요없다.)
종종 Machine learning 을 평가할 때, 인간 수준과 비교하는 것이 많은 도움이 된다. 첫째로 ML algorithm 들이 인간을 점차 능가하고 있기 때문이며, Machine Learning 모델 설계시 인간이 할 수 있는 것들을 흉내내거나 비교하면서 진행하는 것이 효율적이기 때문이다. 이론적으로 Classification 문제에서 최고의 성능은 Bayes Optimal Error 를 능가할 수 없는데, 따라서 Bayes Optimal Error 와 Human Error 등을 성과 측정시 같이 비교해 보는 것이 의미가 있다.
학습의 가장 큰 목적은 Bias, Variance 를 동시에 줄이는 것이다. Human Level 과 Training Error 의 차이를 Avoidable Bias 라고 하고, Training Error 와 Dev Error 차이를 Variance 라고 한다. 학습 결과 얻어진 Avoidable Bias 와 Variance 를 확인하고 어떤 쪽을 줄이는 것에 집중할지를 판단해야 한다.
Avoidable Bias 가 큰 경우에는 더 큰 모델을 사용하여 학습하거나 더 나은 최적화 알고리즘을 써야 한다. 아니면 아예 다른 모델 아키텍처를 찾아야 할지도 모른다. Training Error 는 작은데 Dev Error 가 커서 (즉, Data 에 따른 편차가 들쭉날쭉한 경우) Variance 가 큰 경우에는 더 많은 데이터를 확보하거나 Regularization 기법들을 사용해야 한다. 어쩌면 또 다른 모델을 찾아야 할 수도 있다.
히어로 인터뷰는 “Andrej Karpathy” 이다.
Week2. ML Strategy (2)
우선 오류분석 부분에서는 선택과 집중을 하라는 조언을 한다. 데이터들 중에 오류가 많이 나는 부분이 있다면 그 오류가 나는 부분을 개선하기 위해서 (예를 들면 흐릿한 이미지의 분류 정확도가 다른 이미지들에 비해 현저히 낮을 경우) 노력해야 한다고 말한다. 또, 이미지 라벨 자체가 잘못 분류된 경우에도 이미지의 갯수가 매우 많이 때문에 일일히 대조하면서 발라내는 것은 여간 많은 시간이 필요한게 아니기 때문에, 이 경우도 오류분석을 하면서 잘못 분류한 경우가 잘못된 라벨로 인한 것인지 확인해 보고 전체 Error 대비 차지하는 비중을 생각해서 진행하라고 충고한다.
그리고 가장 기억나는 조언은 “일단 모델을 만들고, Iteration 을 돌려보라” 는 것이다. 모든 걸 고려하기 위해서 이것저것 준비만 하다보면 정작 모델링 착수가 늦어지기 때문에 우선적으로 모델부터 만들어 돌려 볼 것을 조언한다.
많은 프로젝트에서 겪는 문제는 Data 부족이다. 혹은, 적용할 Application 과 학습한 데이터의 분포가 다를 경우이다. 만약 학습한 데이터는 인터넷으로부터 얻은 대량의 데이터이고, Test 는 mobile 이미지로 해야 한다면, 이를 모조리 섞어서 Random Shuffling 할 것인가? 하는 물음에 그렇게 하는것 보다는 dev/test 는 모두 mobile 이미지를 쓰고 train set 에 일부 mobile 이미지를 넣으라고 조언한다. 즉, 적용할 application 에 사용될 이미지로 dev/test set 을 써야 한다는 것이다. 정작 적용할 application 이미지가 dev/test set 에 소수 포함된다면 application 의 성능을 보장하기 어렵기 때문이다.
다른 한편, Transfer Learning 에 대해서 다룬다. Transfer Learning 은 기존에 학습한 내용을 다른 출력 결과물에 대해서도 사용하는 것인데, 일반적으로 잘 학습된 네트워크의 초기 은닉층의 결과를 공유할 수 있는 경우에 사용한다. 또 End-to-End Deep Learning 부분에서는 Hand-Engineering 을 안하고 데이터로만 학습하는 추세를 설명하는데, 별도의 Engineering 작업 없이 Deep Learning 으로 모두 해결하는 것을 의미한다. 결국 데이터만으로 잘 학습되는 부분이 어느 부분인지 잘 판단하는 것이 중요하다.
강좌3은 개인적으로 너무 에너지 소모가 컸다. 추후에 실전적인 문제를 접하면서 다시 한번 음미해 볼 가치가 있는 부분들이 많다는 생각이 들었다.
Course4. Convolutional Neural Networks
Week1. Foundations of Convolutional Neural Networks
아마도 Specialization 강좌 전체에서 2개 강좌만 고르라면 Course1. 과 Course4. 를 고르겠다. 나 뿐 아니라 다른 사람들도 대개 비슷한 대답을 할 것이라 생각된다. Course 2. 와 3. 은 실전적인 부분이라 경험이 축적돼야 공감이 간다. Course5. 의 RNN 은 추상화가 너무 많이 되어 있어서 내부를 이해하기 어렵다. 그에 비해 CNN 은 아주 매력적이다. 왜냐하면 Image 자체가 점, 선, 면, 사물로 발전해 나가는 과정을 Layer 들을 통과하면서 지켜볼 수 있기 때문이다. 마치 눈에 잘 잡히지 않던 Weight Matrix 들의 내부를 들여다 보고 있다는 생각을 갖게 해 준다. (실제로는 숫자이다.)
첫 번째 주차에서는 CNN 으로 항해하기 위한 기초 학습을 한다. Edge Detection Filter 등으로 Convolution 연산이 어떻게 작동하는지 (Filter 를 메기는 방법; 나는 먹인다는 의미로 메긴다는 표현을 쓰겠다.) 를 알아보고 Padding 및 Stride 를 적용하는 것 Max Pooling 을 적용하는 방법을 확인한다. 또 Volume (3-D) 에 대한 Convolution 도 배워본다. Filter 가 여러 개가 되면 Convolution 의 층도 Filter 의 개수만큼이 된다.
자세한 내용은 강의 비디오를 통해 확인하기 바란다. 한 가지 공식만 기억해 두자.
n^{[l]}=\lfloor\dfrac{n^{[l-1]}+2p-f}{s}+1\rfloor( n^{[l]} : l’th layer image size, n^{[l-1]} : l-1’s layer image size, p : padding, f : filter size, s : stride )
Convolution 이 전개되다보면, 마지막에는 Flatten 이 필요한데 이는 Convolution Layer 를 일렬로 하나의 Vector 로 만드는 것을 말한다. 그럼 최종 Vector 값에서 가장 큰 확률을 갖는 요소로 Classification 할 수 있다. Convolution 에서 사용되는 용어는 Convolution (CONV), Pooling (POOL), Fully Connected (FC) 등이다.
히어로 인터뷰는 뉴욕대의 Yann LeCun 교수님이다. GRU 로 유명한 조경현 교수를 초청해서 공동연구 하고 있는 것으로 알고 있다.
Week2. Deep convolutional models: case studies
CNN 2주차부터 RNN 끝날 때까지는 다양한 Case Study 들이 등장한다.
Deep Learning 을 잘 이해하기 위해서 다른 사람들의 작업을 참고하는 것이 큰 도움이 된다고 한다. 내가 하고자 하는 것과 유사한 작업들을 참고하고, 소스도 GitHub 에서 내려 받아 보고 내가 모르는 프레임워크면 같이 프레임워크도 공부하면서 필요한 DataSet 도 내려 받고 돌려보면서 익히는 것이 가장 좋다는 말이다. 그런 후에 그것들을로부터 영감을 받아서 나만의 모델을 만들고 발전시켜 나가면 된다.
Classic Network 들 중 가장 먼저 나오는 것은 LeNet-5 이다. LeCun 교수가 손으로 쓴 숫자를 인식하기 위한 OCR 용도로 1998년에 낸 논문에 발표한 네트워크 구조이다. 비교적 작은 사이즈의 32×32 이미지 (Gray Scale) 을 여러번 Convolution Filter 를 먹인 후에 마지막 Convolution 층(5×5×16) 을 120개의 Flatten Layer 와 일대일로 연결시킨다.
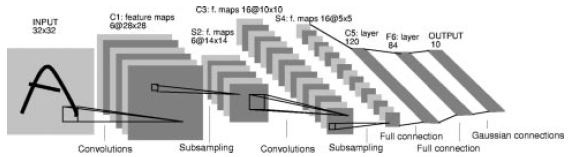
< 그림 출처 : LeCun et al, 1998: Gradient-based learning applied to document recognition >
LeNet-5 에서도 언급되었지만, Convolution 을 메길 때, 인풋 아웃풋 Channel 개수가 다르면 어떻하냐고? 이 부분이 가장 어려운 부분인데, 매번 Volume (3-D) Filter 를 이전층 전체에 대해 메겨서 아웃풋 출력 Channel 만큼 Filter 를 갖고 생성해야 하나? 이 논문에선 그렇게 하지 않았다. 일부러 다른 조합으로 일부의 Channel 들만 사용하도록 고안되었다. (아래 그림 테이블의 s2 ↔ c3 연결 정보 참조)
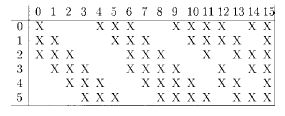
따라서 다른 Network 들에서도 이전 층 전체를 모두 연결시킨다는 가정은 하지 않는 것이 좋겠다. 가장 확실한 것은 네트워크에 대한 설명이 나온 논문을 읽어봐야 한다.
다음으로 나오는 Case-Study 는 Alex Net 이다. ImageNet Challenge 에서 Deep Learning Algorithm 으로 인간 수준에 도달하여 세상을 깜짝 놀라게 했던 그 모델이다. LeNet-5 와의 가장 큰 차이점은 ReLU 를 Activation Function 으로 사용하였고, 2개의 GPU 를 사용하여 병렬연산을 처리하였다는 부분이다. 마지막으로 소개되는 것은 VGG-16 이다. 굉장히 간단한 Filter 와 MAX-POOL 을 적용하고 있는데, 3×3 Convolution Filter 와 2×2 MAX-POOL 을 사용한다. Network 자체는 굉장히 깊다. (여러 층을 사용한다.) Network 가 깊은 것에 비해 Simple 하다고 하는 점은 Convolution Layer 와 Pooling Layer 가 일관되게 반복되면서 Convolution 은 Padding 을 줘서 동일한 사이즈를 가져가고, Pooling 에서만 크기가 줄어든다는데 있다.
이전 층의 결과를 다음 다음 층에 넣는 Residual block 을 사용하는 ResNet 도 학습한다. 즉, a^{[l+2]}=g(z^{[l+2]}+a^{[l]}) 를 사용하는데 이런 Residual block 이 계속 반복된다. 층이 깊어져서 실전에서 학습 성능이 역전되는 현상이 없는 것이 특징이다. 그것은 Residual Block 들이 Identify function 의 역할을 수행하여 뒷단까지 유지시켜준다는데 이유를 찾을 수 있다.
1×1 Convolution Filter 를 사용하여 중간 단계의 Convolution Layer 를 미리 만들어 두면, (Channel 을 줄인) 연산량을 줄일 수 있다는 점이 장점이 있다. 이 Filter 를 사용하는 Network 가 구글에서 개발한 Inception Network 이다. 3×3 이나 5×5 Convolution 을 적용하기 앞서서 1×1 Filter 를 적용하는 것이 Inception Network 이다.
딥러닝 오픈소스를 사용함에 있어서, 이런 Network 들을 스스로 구현하는 것은 매우 어려운 일이다. AI 관련 박사과정 학생에게도 어려운 일이라고 한다. 따라서 Andrew Ng 교수님이 강조하는 것은 GitHub 등에서 이를 다운로드 받아서 사용하라는 것이다. 그리고 강좌3. 에서 말한 Transfer Learning 을 이용하라고 말한다. 학습 자체에 걸리는 시간도 무시할 수 없기 때문에 학습된 결과를 그대로 가져다 사용하라는 것이다. 이 때 단지 내가 구별할 내용이 오픈 소스의 그것과 다르다면 출력층만 바꾸면 된다. 내가 데이터를 많이 확보하고 있다면 소스만 가지고 전체를 학습시키면 되고 그렇지 않다면 학습된 가중치까지 사용하라고 조언한다.
이 주차부터는 Keras 예제가 등장한다. 처음 접해봐서 당황하기도 했는데 이후 RNN까지 계속 저 수준 언어(Tensorflow 를 Wrapping 함) 인 Keras 를 사용하게 된다. Keras 의 기초적인 부분을 학습해 볼 필요가 있다.
Week3. Object detection
3주차에서는 YOLO (You Only Look Once) 알고리즘을 활용하여 Object Detection 에 사용하기 위한 이론적인 부분을 배우고, 이를 적용해 보는 것을 학습한다. 이 주차의 최종 Goal 은 YOLO Algorithm 을 통해서 자율 주행자동차에 필수적인 자동차나 표지판, 사물 등을 감지하는 방법을 학습한다.
Image 자체가 무엇인지 알아내는 것이 Image Classification 이라고 한다면, Image Localization 은 찾아낸 이미지가 어디 위치하고 있는지 표시하는 것까지를 의미한다. 이는 Bounding Box 로 표현되는데, 단일 사물에 대한 이러한 작업을 특정 이미지에 나타난 모든 사물에 대해서 수행하게 되면 Object Detection 을 수행할 수 있다. 비단 Bounding Box 형태가 아닌 좌표들의 집합이나 그래프 형태도 가능하다 이것을 Landmark Detection 이라고 한다. 이런 단계들을 통해서 Object Detection 이 가능하게 된다.
사물을 감지하기 위해서 Sliding Window detection 등의 알고리즘을 사용한다. 이는 이미지 전체를 특정 윈도우로 탐색해 나가는 것인데, 윈도우 이미지를 Crop 해서 탐색하는 방법 대신 Convolution Network 을 사용하면 한 번의 연산으로 사물의 위치를 찾아낼 수 있다. 하지만 여기서도 단점이 있는데 바로 Bounding Box 위치가 정확하지 않다는 것이다.
여기서 YOLO Alorithm 이 등장한다. 이미지의 영역을 그리드 셀로 분할한 뒤 각 영역에 물체가 있는지 여부, 해당 물체의 Bounding Box (x, y좌표 및 높이와 너비), 그리고 Label 의 One-hot encoding 값 등이 결합된 Vector 를 계산한다. 해당 그리드 셀로 겹치는 물체는 일정 임계값을 갖고 해당 셀로 속하는지 판단하게 되는데 이를 IoU (Intersection over Union) 이라고 한다.
한편으로는 동일한 물체에 대해 여러 Cell 에서 탐지되는 것을 방지하고자 Non=max Suppression 기법을 사용해 단일 물체가 단일 셀에서만 감지되도록 한다. 지금까지는 하나의 셀이 하나의 물체만 감지하였는데, 하나의 셀이 여러개의 물체를 감지하게 할 수 있다 그것이 Anchor Box 를 사용하는 것이다. 실습 과제에서는 이것들을 종합하여 실제 자동차 주행중 얻어진 이미지를 사용하여 각 이미지들의 Labeling 된 데이터를 기반으로 새로운 이미지에 대하여 자동차를 감지하는 것을 실습해 본다.
Week4. Special applications: Face recognition & Neural style transfer
CNN 의 마지막 주차에서는 얼굴 인식과 Style Transfer 기법을 알아 본다. Andrew Ng 교수가 Baidu 의 입구를 통과하는 산뜻한 설정이 등장하기도 한다. 이 때 Yuanqing Lin 이 다시 등장한다. 얼굴 인식 기술이 중국에서 매우 빠르게 성장하고 있다고 말한다. 그렇다. 이미 중국과 한국의 격차는 말도 안 된다. 일단 AI 전문가에 대한 대우 자체가 다르다. 기업들이 일부 노력하고 있지만 학교는 멀었다.
얼굴 인식은 크게 Verification 과 Recognition 으로 나뉜다. Verification 은 내 정보가 맞는지만 확인하면 된다. 여권이나 모바일 폰의 Unlock 을 생각하면 된다. 그에 비해 Recognition 은 나의 얼굴이 DB에 저장된 얼굴 중 어떤 사람의 얼굴인지 대조하여 나를 찾는 문제이다.
One-Shot Learning 문제는 얼굴인식의 특성에 대해 이야기 한다. 즉, 학습에 사용할 이미지가 하나인 경우가 많기 때문에 Deep Learning 을 적용하기 어렵다. Siemese Network, Triplet Loss 등의 기법이 등장한다.
다음으로 등장하는 부분은 Neural Style Transfer 이다. Content 이미지와 Style 이미지를 구분하고 이 둘을 조합하는 방식이다. 이 둘을 조합하면 Generated Image 를 갖는다. Generated Image 와 원본 Content Image 간의 비용함수와 Style Image 간의 비용함수를 각각 구해서 가중치 합을 통해 전체 비용함수를 산정할 수 있다. 처음에는 G 를 초기화한다. Gradient Descent Algorithm 을 적용하게 되면 점점 G 이미지가 Content Image 에 Style 이 적용된 것으로 변하게 된다.
이 강좌의 마지막은 얼굴인식과 Style Transfer 를 직접 적용해 보는 것이다.
Course5. Sequence Models
Week1. Recurrent Neural Networks
RNN 모델은 Coursera 강좌를 통해서 처음 접하게 되었다. 따라서 무척이나 생소했는데, 결과적으로 내부 구조를 깊게 이해하긴 어려웠다. 그것은 마치 전자 회로를 구성하는 것처럼 (IC 칩들을 배열하고, 그 IC 칩 내부의 회로는 별개로 또 하나의 Circuit 이 되는 것 처럼) 보이기도 했다. 기본적으로 수십개의 층들이 나열되며 현란한 Block 들이 연속되기 때문에 중간에 길을 잃을 수도 있다. 이 강좌5. 의 또 다른 특징은 짧은 강의 시간 내에 담지 못하는 내용들을 실습 과제에서 보완하고 있다는 점이다. 실습 과제의 빈 칸 채우기는 Keras 소스를 채우는 것인데 실은 그것보다는 강의의 보조적인 느낌이 더 많이 든다.
Sequence 데이터의 예제로는 음성 인식, 음악 작곡, 만족도 평가, DNA 서열 분석, 기계 번역 등을 들 수 있다. 각각의 Sequence 형태가 조금씩 다른데 이 부분에 따라서 적용되는 모델도 달라지게 된다. 우리가 사용하게 될 RNN 의 경우 기존의 Deep Neural Network 구조를 사용하지 않는데, 일단 X와 Y 값의 크기가 다르기 때문이다. 기계번역의 경우 X 인풋이 반드시 Y 아웃풋에 대응되거나 하지 않기 때문이다. 음악 작곡의 경우는 단순한 ‘장르’ 같은 인풋에 대해 음악 전체를 만들기 때문에 애초에 인풋, 아웃풋 Pair 가 맞지 않는다.
자연어 번역 처리 예제를 통해 RNN 표기법을 익힌다. 각 음절(또는 단어) 하나하나가 X^{<t>} 값이 되고 이에 대응되는 것이 Y^{<t>} 라고 할 수 있다. Back Propagation 에서 손실 함수는 개별 Y^{<t>} 에 대응하는 손실함수의 합이 된다.
자연어 처리에서는 조건부 확률 (Conditional Probability) 를 사용하여, 각 Y^{<t>} 가 X^{<t-1>} 이 조건으로 주어질 때의 확률을 계산한다. 특정 Sampling 을 수행하기 위해서는 학습된 내용을 바탕으로 네트워크를 따라가기만 하면 된다. <EOS> 가 나올 때까지 진행하면 하나의 Sample 을 얻을 수 있다. 이런 단순한 RNN 모델의 치명적인 단점이 존재하는데 일찌감치 앞에 나온 단어는 네트워크의 뒷단에서 영향력이 미미해 진다는 것이다. 이런 문제를 극복하기 위해 다양한 모델들이 개발되었다.
대표적인 모델이 GRU (Gate Recurrent Unit) 인데, 이것은 뉴욕대의 조경현 교수가 2013년에 최초 제안한 것이다.
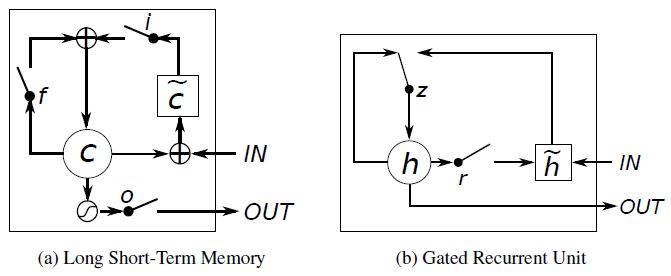
<그림 출처 : Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, Yoshua Bengio, 2014, Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling>
GRU 보다 6년이나 먼저 제안된 구조가 LSTM (Long short-term memory) 인데, 이 모델 역시 잘 작동한다고 한다. (둘의 차이점 및 특징에 대해서 설명하기에는 아직 내 수준이 한참 모자라서 더 공부한 뒤에 포스팅 하도록 하겠다.)
한편 한 방향으로만의 정보 흐름이 번역에 불리하다고 생각되어 고안된 구조가 BRNN (Bidirectional RNN) 이다. 즉 한 방향만으로 정보를 넣는 것이 아닌 뒤쪽의 노드에서 앞쪽으로 전달한 것도 인풋으로 삼는 구조이다.
1주차에 배운 내용도 무지막지하게 많고, 내용도 처음 접하는 내용들이라 어려웠는데 실습이 3개 인 것을 보고 좌절한 순간도 있었다. RNN Building Block 을 만들어 보는 실습과 이를 응응하여 음절단위의 공룡이름을 생성해 보는 실습이 있다. 그리고 LSTM 네트워크를 학습하여 Jazz 음악을 생성하는 재미있는 실습도 있다.
Week2. Natural Language Processing & Word Embeddings
2주차의 내용은 NLP (자연어 처리) 와 Word Embedding 이다. 사실 Word Embedding 이 어떤 개념인지 몰랐는데, 강의를 통해서 Featurized Representation 을 사용한다는 것을 알게 되었다. 예를들어, 10,000개의 단어 사전이 있다고 하면 개별 단어는 모두 10,000 개의 원소를 갖는 vector 로 표현되지만 차원을 축소하여 300개의 차원으로 줄이게 되면 각 단어는 300개의 Feature 에 대응되는 값을 가진다. 이를 embedding 이라고 하는데 이렇게 embedding 된 vector 를 인풋으로 하여 RNN 에 태우게 된다.
RNN 의 구체적인 연산 메커니즘에 대해서는 제대로 이해를 하지 못했는데, 각 단어가 RNN 네트워크에서 순서대로 인풋이 되어 최종 결과를 얻는데 사용된다. 과제 실습에서는 Sentiment Classification 이라고 하여, 평점 주기를 구현하는데, 처음에는 단순히 Embedding Vector 들을 동일 차원에서 평균내서 사용하고, 좀 더 발전된 단계로 LSTM block 들을 연결한 RNN 구조를 생성한다. Sentiment Classification 의 아웃풋은 평점의 개수로 표현되는 One-Hot Vector 로 Softmax 를 타게 된다.
과정에서 Word2Vec 라 GloVe, Negative Sampling 같은 개념을 배우게 되는데 Softmax 수식을 정확히 이해가 안 되어 좀 더 살펴 봐야 할거 같다. 어떤 이유에서 어떤 식으로 해당 기법들이 사용되는지를 좀 더 확인해 봐야겠다. 시간에 쫓기며 보다보니, 디테일한 부분에서 대강 이해하고 넘긴 부분들이 많았던거 같다.
그리고 Debiasing 부분도 배우는데 예를들면, Man : Computer Programmer as Woman : Nurse 와 같이 특정 단어가 성별이나 종교, 나이, 성적취향 등에 한정적으로 치우치는 것을 방지하기 위한 기법이다. 이를 위해서는 특정 Feature 에 편향된 단어들을 찾아서 해당 Feature 에 중립적이 되도록 Embedding Vector 를 조정해 주어야 한다. 이의 수학적 기법은 실습 과제에서 익힌다.
Week3. Sequence models & Attention mechanism
긴 여정의 마지막 주차이다. 마지막 주차에서는 Machine Translation (기계번역) 과 Speech Recognition (음성 인식)을 다룬다. 기계번역과 Image Captioning 은 기본적으로 같은 모델 형태를 취한다. 그것은 Encoder 와 Decoder 로 구조를 말한다. 단지, Image Captioning 은 Convolution 을 적용한 마지막 Flatten 층을 Encoder 로 사용하는 형태이다.
기계번역을 위해서는 Encoder / Decoder 구조의 RNN 을 사용하게 되는데, X 라는 인풋 Vector 가 주어진 상황에서의 Y 의 조합의 최대 확률을 찾는 문제가 된다. ( Most likely sentence given sentence ; conditional language model ) 여러 가지 기법이 있겠지만, 강의에서 소개하는 것은 Beam Search 를 활용한 방법이다. Beam Window 의 개수를 정해놓은 상태에서 Y1 부터 Y2, … 이렇게 확장해 나갈 때 가장 높은 확률을 갖는 Beam 만 선택하여 계속 이어나가는 형태이다.
기계번역의 평가도 매우 중요한 요소인데, 하나의 문장도 여러개로 번역될 수 있는데 사람이 번역한 모범 답안이 여러개 일 때, 기계번역의 질을 평가하는 방법 중에 하나로, Bleu Score 방법이 있다. 이것은 n-gram 으로 단어들을 합쳐서 번역의 질을 평가하는 지표를 만든다. 그리고 기계번역을 RNN 에 적용하기 위해서 Attention Model 을 도입한다. 너무 복잡한 구조라 잘 이해가 가진 않았다. 실제로 번역에 사용할 마지막 RNN 층 하위에 또 다른 B-RNN 층을 두고 Attention 계수들로 Context 를 만들어 인풋으로 사용하는 구조인데, 정확히 어떤 매커니즘인지 이해하기 어려웠다.
마지막으로 학습하는 내용은 음성인식 부분이다. 전통적으로 phoneme (음소) 를 하나하나 매핑시키는 방법에서 벗어나 RNN 을 통한 audio clip 을 transcript 로 전환하는 식으로 발전되었다. 예를들면, RNN 을 통해 얻어낸 음소들 중에서 연결된 음과 분리된 음소를 구분하는 방법을 취하며 동일 음소를 하나로 병합하는 식이다. 그리고 Trigger Word Detection 부분에서는 최근 흔하게 사용하는 AI 스피커를 깨우기 위한 (또는 끄기 위한) Trigger Sound 를 인식하는 방법을 배운다.
실습 과제에서는 Attention Model 에 대해서 좀 더 자세히 다루고, Trigger Word Detection 을 실제 음성 파일을 통해서 다룬다. 이 실습예제는 전체 5 강좌중에서 분량면에서 최고 길이를 자랑한다. 노이즈 음성에 Trigger sound 를 집어 넣어 합성하고, 동일 시간 간격으로 사각파를 만들어서 Train Data 로 활용한다. 여러개 음성 파일로 학습을 시키고 최종적으로 테스트를 한다.
Andrew Ng 교수님의 감사 인사를 끝으로 길었던 과정이 모두 끝났다. 5개 강의 어느 하나 소홀히 여길 수 없는데, 5강은 특히 어려웠던거 같다. 왜냐하면 구현 자체가 Keras 로 진행되고 LSTM 이나 GRU 자체를 제대로 이해하지 못했기 때문이다. 가장 중요한 강의를 꼽자면 역시 1강이다. 1강의 Forward Propagation 과 Backward Propagation 을 반드시 이해해야 Deep Neural Network 의 기본 매커니즘을 이해할 수 있다.
강의에서 얻은 점은 Python Code 를 조직화 하는 부분과 Transfer Learning 을 통해서 학습된 모델을 재학습 할 수 있다는 점. 그리고 Open Source Framework 은 어느 하나를 판다기 보단 필요한 경우에 GitHub 에서 내려받아서 익힐 것. 그리고 RNN 과 CNN 은 각 활용분야의 논문들을 읽어보아야 한다는 것. 정도가 되겠다. 사실 수박 겉핡기만 하는 국내 강의들에 비해서 상당히 알차고 추천할 만하다고 생각한다.
I know this if off topic but I’m looking into starting my own blog and was wondering what all is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very web smart so I’m not 100% positive. Any recommendations or advice would be greatly appreciated. Kudos
Thank you for commenting me. Actually I’ve set this blog by using WordPress. I am using Amazon Cloud Service called “Amazon Lightsail Service” which costs 3.5$ per each month. At the first time, I used Amazon E2C Service but it costs much than I expected and even I couldn’t assess the expected amount I’ve used so that I quit that and I transferred to this Lightsail service. It’s very fit to this blog like services. I’ve chosen the WordPress pre-installed service. For the Domain Service, I’ve used Godaddy which might cost 20$ per year and I’ve added Security Service so it cost about 40$ per 2 years. If you wish to use WordPress, you should buy some “WordPress Theme”, otherwise your web pages look very poor. I bought “GeneratePress” Theme for permanent uses. (Of course there may be some upgrade costs, if you manage the latest version of it, it depends on your thought)
Isn’t it helpful? If you have any other inquiries, let me know. Thanx.
I have been exploring for a little bit for any high quality articles or blog posts in this kind of area .
Exploring in Yahoo I ultimately stumbled upon this web site.
Reading this info So i’m satisfied to show that I’ve an incredibly good
uncanny feeling I found out exactly what I needed.
I most definitely will make certain to don?t omit this
site and give it a look regularly.
Thank you for your cheers. I will try to post more. Nowadays I am a bit busy but if I have some free time, then I will do.